
В последние годы учёные-компьютерщики создали различные высокоэффективные инструменты машинного обучения для создания текстов, изображений, видео, песен и другого контента. Большинство этих вычислительных моделей предназначены для создания контента на основе текстовых инструкций, предоставляемых пользователями. Исследователи из Гонконгского университета науки и технологии недавно представили AudioX — модель, которая может генерировать высококачественные аудио- и музыкальные треки, используя в качестве входных данных тексты, видеоролики, изображения, музыку и аудиозаписи. Их модель, представленная в статье, опубликованной на сервере препринтов arXiv, основана на диффузионном трансформере — продвинутом алгоритме машинного обучения, который использует так называемую архитектуру трансформера для создания контента путём постепенного шумоподавления входных данных.
Как интеллектуальные системы могут достичь единого мультимодального понимания и генерации
Творчество человека — это seamlessly интегрированный процесс, в котором информация из разных сенсорных каналов естественным образом объединяется мозгом. Традиционные системы часто полагались на специализированные модели, неспособные уловить и объединить эти внутренние связи между модальностями.
Вэй Сюэ, автор-корреспондент статьи, в интервью Tech Xplore
Основной целью недавнего исследования, проведённого Вэй Сюэ, Ике Го и их коллегами, была разработка единой системы обучения представлениям. Эта система позволила бы одной модели обрабатывать информацию в разных форматах (например, тексты, изображения, видео и аудиодорожки) вместо того, чтобы комбинировать отдельные модели, которые могут обрабатывать только определённый тип данных.
Мы стремимся к тому, чтобы системы искусственного интеллекта формировали мультимодальные концептуальные сети, подобные человеческому мозгу.
Вэй Сюэ, автор-корреспондент статьи, в интервью Tech Xplore
Эксперт добавил, что AudioX, созданная модель, представляет собой смену парадигмы, направленную на решение двойной задачи — концептуального и временного согласования. Другими словами, она предназначена для одновременного решения вопросов "что" (концептуальное согласование) и "когда" (временное согласование). Конечной целью является создание такой модели мира, которая будет способна прогнозировать и генерировать мультимодальные последовательности, которые соответствуют реальности.
Новая модель на основе диффузионного трансформатора, разработанная исследователями, может генерировать высококачественные аудио- или музыкальные треки, используя в качестве ориентира любые входные данные. Эта способность преобразовывать "что угодно" в звук открывает новые возможности для индустрии развлечений и творческих профессий. Например, позволяет пользователям создавать музыку, подходящую для конкретной визуальной сцены, или использовать комбинацию входных данных (например, текстов и видео) для создания желаемых треков.
AudioX построен на архитектуре диффузионного трансформатора, но его отличает мультимодальная стратегия маскировки. Эта стратегия в корне меняет представление о том, как машины учатся понимать взаимосвязи между различными типами информации.
Вэй Сюэ, автор-корреспондент статьи, в интервью Tech Xplore
Специалист добавил, что скрывая элементы в разных входных модальностях во время обучения (например, выборочно удаляя фрагменты из видеокадров, токены из текста или сегменты из аудио) и обучая модель восстанавливать недостающую информацию из других модальностей, мы создаём единое пространство представлений".
Напомним, что AudioX — одна из первых моделей, объединяющих лингвистические описания, визуальные сцены и звуковые паттерны, улавливающая семантическое значение и ритмическую структуру этих мультимодальных данных. Её уникальная конструкция позволяет устанавливать связи между различными типами данных, подобно тому, как человеческий мозг интегрирует информацию, полученную с помощью разных органов чувств (зрения, слуха, вкуса, обоняния и осязания). Сюэ подчеркнул, что, речь идет о единой платформе, которая поддерживает широкий спектр задач в рамках одной архитектуры модели. Она также обеспечивает кросс-модальную интеграцию с помощью нашей стратегии мультимодального обучения с маскировкой, создавая единое пространство представления. Она обладает универсальными возможностями генерации, так как может обрабатывать как обычное аудио, так и музыку с высоким качеством, обучаясь на крупномасштабных наборах данных, включая наши недавно созданные коллекции".
В ходе первоначальных испытаний было обнаружено, что новая модель, созданная Сюэ и его коллегами, создаёт высококачественные аудио- и музыкальные треки, успешно интегрируя тексты, видео, изображения и аудио. Её самая примечательная особенность заключается в том, что она не объединяет разные модели, а использует один диффузионный преобразователь для обработки и интеграции разных типов входных данных.
AudioX поддерживает различные задачи в рамках одной архитектуры, от преобразования текста/видео в аудио до наложения звука и завершения музыки, выходя за рамки систем, которые обычно справляются только с определёнными задачами. Модель может иметь различные потенциальные применения, в том числе в кинопроизводстве, создании контента и играх.
Вэй Сюэ, автор-корреспондент статьи, в интервью Tech Xplore
В скором времени AudioX можно будет усовершенствовать и использовать в самых разных сферах. Например, он может помочь творческим специалистам в создании фильмов, анимации и контента для социальных сетей. Ученые предложили читателям статьи представить, что будетрежиссёру больше не нужен звукорежиссёр для каждой сцены. AudioX может автоматически генерировать шаги по снегу, скрип дверей или шелест листьев, основываясь исключительно на визуальных кадрах. Точно так же его могут использовать инфлюенсеры, чтобы мгновенно добавлять идеальную фоновую музыку в свои танцевальные видео в TikTok, или ютуберы, чтобы дополнять свои видеоблоги о путешествиях аутентичными местными звуками — и всё это по запросу.
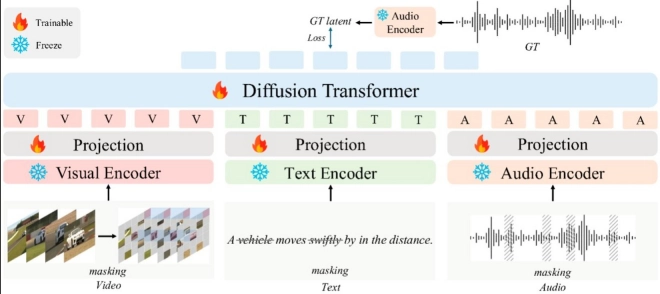
В будущем AudioX также может быть использован разработчиками видеоигр для создания захватывающих и адаптивных игр, в которых фоновые звуки динамически подстраиваются под действия игроков. Например, когда персонаж переходит с бетонного пола на траву, звук его шагов может измениться, или саундтрек игры может постепенно становиться более напряжённым по мере приближения к угрозе или врагу.
Вместо того, чтобы просто изучать ассоциации на основе мультимодальных данных, мы надеемся интегрировать эстетическое восприятие человека в систему обучения с подкреплением, чтобы лучше соответствовать субъективным предпочтениям.
Вэй Сюэ, автор-корреспондент статьи, в интервью Tech Xplore
Космический корабль Lucy готовится ко второму столкновению с астероидом.
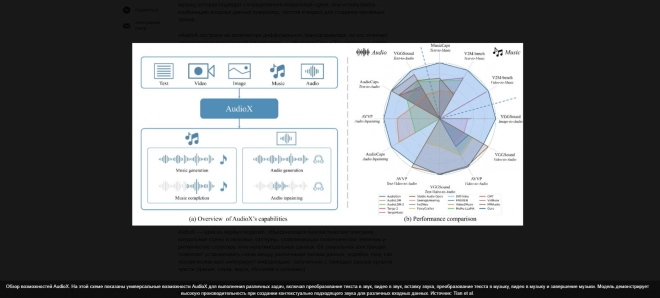
Фото и видео: Ingrid Fadelli , Tech Xplore; Zeyue Tian et al
Обсуждение ( 0 ) Посмотреть все